The Liftoff of Filecoin Secondary Retrieval Markets


Authored by David Ansermino
ChainSafe is excited to announce that we have been working to implement a discovery mechanism to help enable secondary retrieval markets for the Filecoin network, through the support of Protocol Labs.
Overview
The Filecoin network rewards miners for their participation in storing and retrieving files. Within the core protocol there is presently no separation between those who store files (Storage Providers) and those who deliver files to the users (Retrieval Providers). Thanks to some fundamental features of Filecoin, such as content addressing, varying second layer retrieval solutions are made possible. This provides the key benefit of allowing miners to specialize in storage or retrieval, as each have their own demands. We consider this to be a "secondary" market, because it is a layer 2 solution outside of the core protocol.
When one starts to study the components of the existing internet infrastructure (eg. CDNs) it becomes apparent that in order to meet the current expectations of content delivery, systems like Filecoin will need a variety of methods for connecting users with the data they want.
The "last mile" refers to the parts of our internet infrastructure that connect the ISPs to their customers. It is often the most expensive part of any connection and one of the hardest to optimize due to the distribution of customers geographically (they could be very far apart, or in a dense area where installing infrastructure is expensive). Consequently, this infrastructure exhibits limitations common to centralized systems, and provides an opportunity for decentralized solutions to shine.
Gossip-based Discovery
To demonstrate some of these possibilities we built a discovery mechanism using libp2p's gossipsub implementation. The basic user flow looks like this:
-
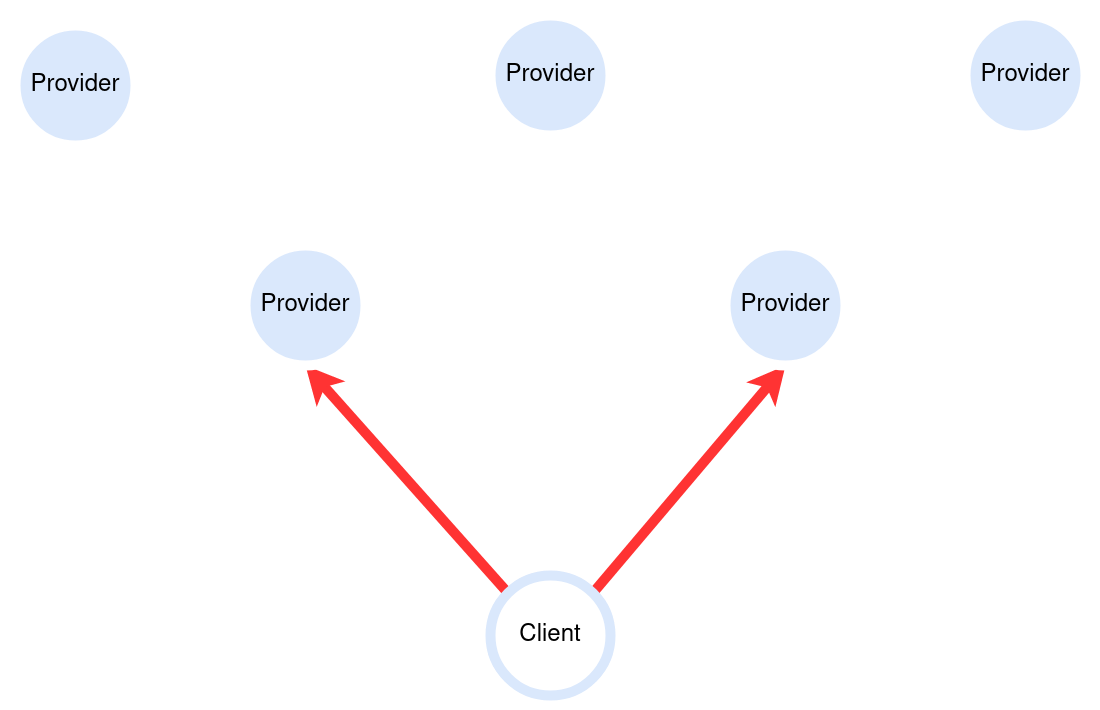
The user submits a query using a Client with a specific CID of the content they are seeking.
-
The Client then sends the query to its peers on the gossip network.
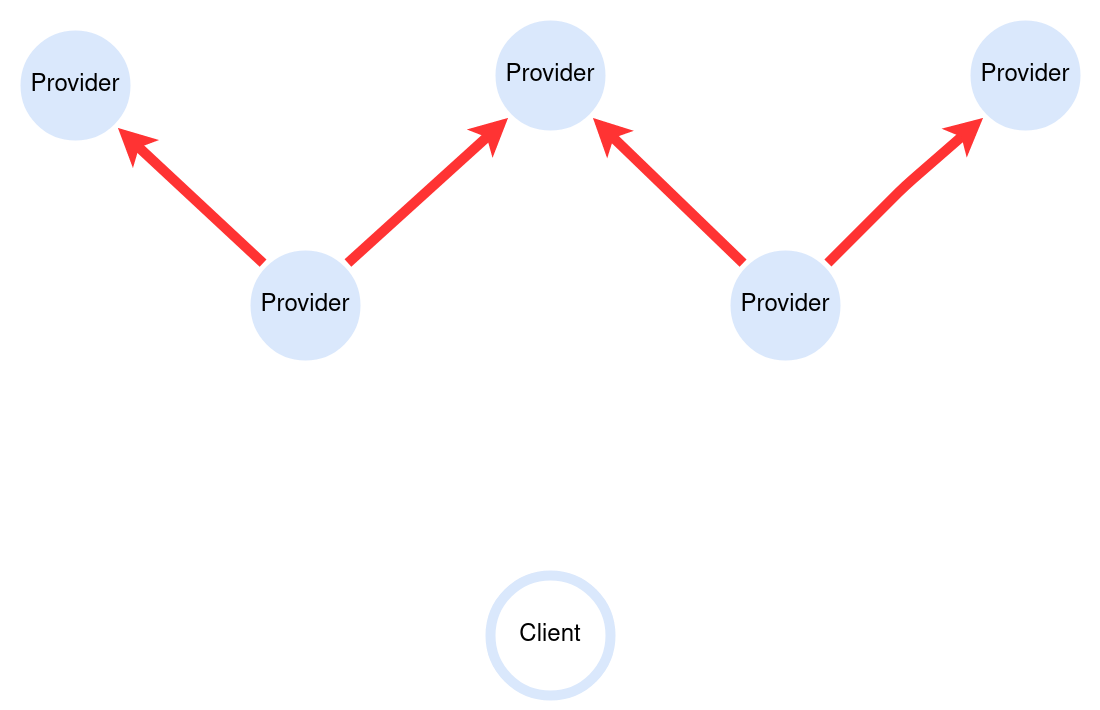
- The peers then pass it on - gossip it - to other Providers.
- If a Provider has the data, they can connect to the client and send back a retrieval offer.
- The Client will then pick the best offer for the data and begin the retrieval.
The implementation of this new discovery mechanism can be found [here](https://github.com/chainsafe/fil-secondary-retrieval-markets/). It provides a Client that can submit queries to a gossipsub network and listen for offers. A basic Provider is also included which checks a datastore for every request and submits offers if it has the data available. The data exchange protocol used to transmit data from the Provider to the Client establishes a payment channel and performs an incremental transfer of funds alongside the data. The components required for this can be found here. More details on how the data exchange protocol works can be found in the Filecoin Spec.
Provider Strategies
This additional discovery mechanism improves the Client's ability to find the data they're looking for. For Providers, it creates new opportunities to participate in the market. In order to be effective Providers must consider several factors. The availability and popularity of any piece of content will need to be accounted for, as the market may respond to basic supply and demand principles. If a Provider needs to fetch some data from the Filecoin network, they will have to consider the cost to themselves for that retrieval.
Providers may adopt a number of strategies. Some Providers may choose to populate their datastores with content from sources other than Filecoin. This could be a sensible approach to avoid the cost of retrieving the data themselves. Another strategy could be to provide a static set of data, perhaps a collection of books that are in the public domain. Furthermore, the market could provide access to data that isn't necessarily stored on Filecoin. With the correct incentives, any piece of data from any source could become valuable to Providers.
Retrieval Markets are an extremely exciting piece of the Filecoin ecosystem. Storage is undoubtedly not very useful if you can't retrieve that data in a way that meets your needs. If we can build systems that caters to a wide variety of use cases, these markets can progress towards even wider adoption as the availability of data increases. The fabric of these markets will be the fundamental data layer that Web3.0 needs for adoption.