Lodestar Holesky Rescue Retrospective
When the Holesky hard fork went sideways, validators struggled through hidden bugs, misconfigured clients, and unexpected chain splits. Here’s how quick thinking, precise fixes, and community teamwork turned a chaotic experience into a valuable lesson for future forks.


Hard fork transition
What happened to Lodestar validators during the Holesky transition?
The Holesky hard fork was scheduled on Epoch115968at 2025-02-24 21:55:12 UTC. Approximately 5 hours prior, the Lodestar team proactively released version v1.27.1 to address a bug. During the transition, some Lodestar genesis (index 695000-794999) and testing validators (running v1.27.0) failed to sync through the hard fork. Subsequently, some started to miss block proposals due to an isolated edge case stemming from a withdrawal credentials bug, causing a state mismatch that corrupted the database. This was fixed in v1.27.1, but it was still determined that both versions of v1.27.0 and v1.27.1 would be compatible with Pectra. However, we recommended, if your node was stuck post fork, to wipe the database and upgrade to v1.27.1 to properly resync.
We also had trouble reproducing and debugging this consensus problem (which also appeared on Gnosis devnets), fixed with v1.27.1. The debugging difficulty was due to challenges collecting the pre-state SSZ object alongside a valid and invalid post-state SSZ object for a then-unknown condition that only happens very infrequently and only on some nodes. By default, none of these persisted, which required us to figure out how to collect them across our fleet to isolate the root cause.
The issue led us to introduce a pull request that would automatically persist the relevant information for future incident analysis: https://github.com/ChainSafe/lodestar/pull/7482.
We confirmed that some of the nodes running the v1.27.1 hotfix successfully transitioned through the fork, prompting us to force a checkpoint sync to the pre-Electra finalized state after upgrading our nodes to v1.27.1 We aimed to get all of our genesis validators attesting to support finality.
Combined, our genesis and testnet infrastructure validators contribute about 6% of eligible ETH, so it was critical that we did this quickly to help push the finalization of the first Electra epoch. We took immediate action before the community even realized there was an issue with the execution clients.
Execution layer issue
While upgrading all of our beacon nodes to v1.27.1, other clients pointed out a large number of invalid blocks. As noted in the Ethereum Foundation's Root Cause Analysis, execution clients did not configure the deposit contract address correctly, and the chain split, with most execution clients agreeing with the problematic block.
For Lodestar, we set up all of our Holesky validators with Geth as the execution client. As the chain forked, our validators had agreed with the majority view of execution clients, indicating that the problematic execution payload at slot 3711006 with the beacon block root 0x2db899881ed8546476d0b92c6aa9110bea9a4cd0dbeb5519eb0ea69575f1f359 was valid, even though it contained the problematic execution payload. This also meant all of our validators had submitted attestations to justify the bad chain containing this beacon block. It was determined later that the minority fork, consisting of Erigon and Reth execution clients, correctly rejected the problematic block.
Since the incident, ChainSafe has planned to run equal distributions of all five execution clients to improve redundancy and speed up turnaround if any execution client experiences issues.
Justification of the problematic block
At 22:44:00 UTC, it was noted that the chain was very close to finalizing, with 65% of eligible ETH voting for the bad fork. This vote was without all of Lodestar's beacon nodes properly in sync due to the v1.27.0disruption in our fleet. This may have helped prevent finalizing the bad chain, as it kept 5-6% of the eligible ETH offline post fork while we resolved the situation.
Execution clients confirmed their findings for what was causing the chain to fork. By then, we had already restarted and confirmed that our validators were on the bad fork of the chain. At that point, it had already been justified in epoch 115968, with 71% eligible ETH.
To prevent finalizing the bad fork, we shut down all our validators at 23:24:00 UTC. Shoutout to Michael Sproul (Lighthouse) for his foresight in taking down the Lighthouse validators early to prevent finalization.
Unfortunately, due to the available information at the time, we pushed and quickly deployed v1.27.1, which was just meant to enable block proposals and attestations post-hard fork. So, before we realized that there was a bug and a chain fork, all of our genesis validators had already committed to slashable surround votes if we were to try and recover the valid minority chain.
We learned that during hard fork transitions, although it is important to finalize the chain promptly for stability post-fork, it is important to verify what is being finalized. Invalid blocks on the network post fork should be promptly investigated and actions should be taken to understand the problem before taking action. Although rare, we understand the reprocussions of running only majority clients which can pose major issues if the majority client(s) is/are incorrect.
Patching execution clients
To produce blocks on the correct minority chain, we needed to upgrade to the patched execution clients. ChainSafe started patching execution clients with the respective Holesky rescue branches at 2025-02-25 00:05:12 UTC. We began restarting nodes using the finalized checkpoint pre-Electra served by EthPandaOps. However, the rescue images got stuck because the problematic block was already in the database, making a database removal necessary.
Our internal plan was to patch, resync, and stabilize our beacon nodes until we could determine how to move forward. None of our validators could produce blocks and help maintain liveness for the minority fork, and at the time, we didn't have any validators running Erigon or Reth execution clients in our infrastructure.
By the end of the night, the core dev community rallied around the priority of stabilizing block production on the "correct" minority chain. Once we could adequately restore liveness, we could approach attestations and potential slashing issues.
Rescuing Holesky
Syncing and fork confirmation issues
Lodestar was consistently struggling to sync to the correct chain due to the justified epoch and the majority of non-upgraded peers continuing to build on the bad chain. We had three methods of determining if we were on the correct chain:
- Verify the bad beacon block was not in the canonical chain via the
/eth/v2/beacon/blocks/3711917API endpoint. - Check that the state root matches those on the correct chain, a small minority of beacon nodes running their consensus clients with Erigon or Reth.
- Using a script developed by Sam at EthPandaOps to check block roots against the beacon node for the correct fork.
Using the beacon endpoint /eth/v1/debug/fork_choice, you can also see how the network processed the invalid block in fork choice. This leads to the conclusion that importing this problematic block optimistically causes Lodestar to have problems pivoting to the minority chain.Because there were multiple viable forks, this added exponential work for all the consensus clients. This led to a resource-heavy load on every node on the network. Dapplion's Devcon SEA presentation on "How long non-finality could kill Ethereum" accurately predicted many of these problems.
In a chaotic forking environment, it becomes tough to know which fork is the correct chain, and finding healthy peers becomes increasingly difficult, if not made worse, by unhealthy nodes continuing to build the wrong chain. Shutting down unhealthy or faulty nodes on the wrong chain may help CLs properly sync new, healthy beacons on the correct chain.
The most important thing we can do in this environment is build blocks to restore liveness on the correct chain. To do so, we need to be able to spin up healthy nodes that we can sync to the same correct canonical chain so the connected validators can produce the desired blocks. One of the most challenging problems was making sure we could point Lodestar to healthy peers to sync to the minority fork the community rallied around.
To prevent Lodestar from re-syncing to the incorrect chain, we developed a feature that a checks for blacklisted blocks and disallows processing. We also check that any subsequent blocks of the invalid chain are also disallowed via https://github.com/ChainSafe/lodestar/pull/7498. Although, there is an argument to be made for abusing of this feature, the worst case could lead to minority chain forking if used improperly, which self-inflicts the node operator.
In addition, a follow up pull request to this feature adds a new endpoint/eth/v1/lodestar/blacklisted_blocksto return the root/slot of any blacklisted blocks. The CLI flag--chain.blacklistedBlocks 0x12345abcdefis a feature that allows you to list 0x-prefixed root hexes for blocks that should not be processed.
Communication is essential for finding healthy peers in a chaotic environment. We need to be able to share trusted peer identifiers of healthy nodes while ensuring that we do not overload them. Healthy nodes bombarded with many requests may lead to performance issues, taking down vital, healthy peers in a fragile environment. Sharing healthy enr: addresses for consensus clients and purposefully using them as bootnodes was the early strategy to sync up more healthy beacons. The community shared documents like this to have some trusted Schelling points for coordination. In our holesky-rescue branch, we added some of these Holesky bootnodes to the image/branch build by default. This also led us to suggest consensus clients implement an endpoint that allows you to add a "trusted" peer, which can bypass some peer scoring heuristics: https://github.com/ChainSafe/lodestar/issues/7559
In Lodestar, you can use the--bootnodesflag to add a list of ENR bootnodes and set--network.connectToDiscv5Bootnodes trueto attempt direct libp2p peer connection to these nodes.
Note that if you want to use Lodestar as a static peer, you must enable--persistNetworkIdentityto ensure your ENR (your network identity) remains the same throughout restarts. Otherwise, it will change.
We currently do not support the trusted peer feature.
Lodestar sometimes struggles with syncing in a network where we may only have one or two useful peers. As noted in https://github.com/ChainSafe/lodestar/issues/7558, we may inadvertently end up banned for not adhering to the rate limit due to overwhelming data requests. The overwhelming data requests still need to be investigated.
Resource usage in a non-finality environment
Resource usage is one of the primary weaknesses of consensus clients in a non-finality environment. Specifically, out-of-memory (OOM) crashes take down healthy nodes, making it harder for others to sync up to the head of the chain. In addition, if a node needs to resync from a previously finalized checkpoint, it becomes a much harder hill to climb for resyncing.
Handling memory usage in this environment is essential, and timing is critical. Fixing memory handling issues and figuring out how to boot from unfinalized checkpoint states will help us sync healthy nodes faster and keep them stable under duress.
Lodestar has a fixed heap memory usage limit set by the nodeJS environment. Our images and builds set this at 8GB (8192 MB), sufficient for a stable network. Generally, when we cannot prune unfinalized states to disk, a memory buildup can cause out-of-memory (OOM) errors, which crashes the node. In our holesky-rescue branch, we increased the heap memory by default in the nodeJS environment to use --max-old-space-size=32768 to allow for 32GB of heap memory.
While other teams tried to sync with Lodestar to the minority fork head, they discovered that Lodestar crashes as it gets close to the head, and we could not properly prune checkpoint states. We covered this issue in https://github.com/ChainSafe/lodestar/issues/7495.
The following fixes were implemented to correctly handle pruning checkpoint states:
https://github.com/ChainSafe/lodestar/pull/7497
https://github.com/ChainSafe/lodestar/pull/7505
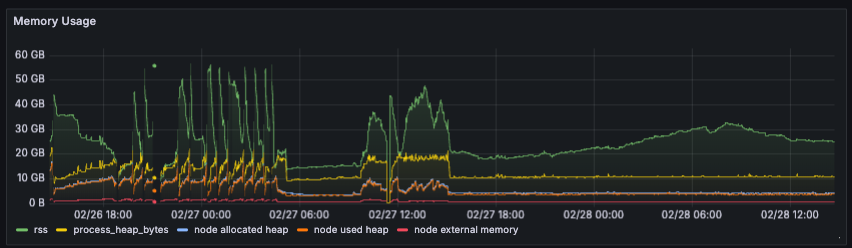
Before the fixes were implemented, we would constantly OOM as memory would grow indefinitely until it exceeded the max limit. In this device's case, the max was set at 60GB. After these fixes, Lodestar generally held memory pretty constantly at around 10-12GB for most of the non-finality period.
Reduce storage by pruning checkpoint states
Besides memory, another bottleneck during non-finality is disk storage requirements. For the Holesky network, checkpoint states can reach as much as ~250MB per state, which consumes about 56GB per day and is another reason why beacon nodes fail to remain in sync during long non-finality periods. With https://github.com/ChainSafe/lodestar/pull/7510, we are able to set DEFAULT_MAX_CP_STATE_ON_DISK to persist a maximum of n epochs on disk to help with storage bloat.
This type of behaviour is generally not safe to do. If you setDEFAULT_MAX_CP_STATE_ON_DISKto100(as we did by default for theholesky-rescuebranch), the node may not be able to process blocks from other potential forks. This isdisabledby default and may be added as a future feature.
Storage feature improvements are currently being developed, such as using binary diff states and/or using ERA files. This should better address storage requirements without using unsafe features to address chain emergencies.
Using checkpointState to jumpstart sync
As the non-finality network persisted, it was getting increasingly difficult for new nodes to get synced to the head of the correct fork over time. In Lodestar, you can set an arbitrary checkpoint state to initiate the sync via --checkpointState /path/to/file/or/url. We got an SSZ state from Serenita (a trusted node operator) that was saved from a synced beacon node on the correct chain. This was a huge timesaver for jumpstarting other beacon nodes. By loading this checkpoint, we could minimize the time required to catch up to the head of the chain and avoid syncing from the last finalized checkpoint.
Using local checkpoint states
During the Holesky rescue, one useful feature that would help in a non-finality environment is the ability to jumpstart nodes utilizing an unfinalized checkpoint. In addition, you need a way to persist the checkpoint state locally for future use and the ability to share the state to help other nodes sync.
With https://github.com/ChainSafe/lodestar/pull/7509, Lodestar is able to use a local or remote unfinalized checkpoint state to reduce the syncing time required when a node is restarted. This allowed new nodes to quickly sync to head, especially as the non-finality period dragged on. In combination with https://github.com/ChainSafe/lodestar/pull/7541, we implemented an API endpoint (eth/v1/lodestar/persisted_checkpoint_state) to return a specific, or latest safe checkpoint state. This feature will help to bring healthy nodes up faster in a turbulent network. Node operators in this environment generally refrain from restarting synced beacon nodes because of the difficulty of resyncing. Some important settings typically require an application restart to take effect, so this feature will help node operators feel more comfortable restarting nodes in future non-finality environments.
Slot import tolerance adjustments
When trying to sync the correct chain, the hardest parts to sync were the early periods of the rescue, where no blocks were being produced and consecutive skipped slots in the hundreds. Our slotImportTolerance was increased from the default 32 because there were periods of greater than one epoch where we would not see one block. The function is important as it prevents Lodestar from building on a head older than 32 slots, which could cause massive reorgs. However, Holesky was suffering from severe liveness issues, and we wouldn't see a block for more than 32 slots. Then, the node would fall back into syncing mode, preventing it from producing blocks. Setting this higher by default for the rescue's early periods helped ensure we could contribute to block production, even though new blocks were rarely seen.
Sync stalls and peer churning
Due to the turbulent network, continuous rate limiting of "bad peers" made it difficult to find good peers to serve us the data we needed. Lodestar would sometimes hit the max target peers, but none of them were viable for advancing our node. Although we experimented with churning a random subset of connected peers when we were stuck, we ultimately implemented a heuristic to start pruning peers when they were starved. During this state, it will attempt to prune additional peers but prioritize keeping peers who are reportedly far ahead of our node: https://github.com/ChainSafe/lodestar/pull/7508
This PR also enhances our/eth/v1/lodestar/peersendpoint to return more details about the status of our connected peers. This includes data such as theirhead_slotwhich can help analyze the health of the network by identifying how many of our connected peers are actually synced to the head.
Example:
{
"peer_id": "17Uiu2HAmPcVbHnDgeFBTKcFtpaLfLfUJaEasdbpsBeT7nbxmmDeh",
"enr": "",
"last_seen_p2p_address": "/ip4/123.456.789.000/tcp/4096/p2p/17Uiu2HAmPcVbHnDgeFBTKcFtpaLfLfUJaEasdbpsBeT7nbxmmDeh",
"direction": "inbound",
"state": "connected",
"agent_version": "Prysm/v5.0.3/2c6e028600d4ad5659f0d25d8911714aa54f9c25",
"status": {
"fork_digest": "0x019e21ad",
"finalized_root": "0xd0285a8ec914f53cf15e9cce336a07c4f11c666e2addec620592d5ff3640ed34",
"finalized_epoch": "115967",
"head_root": "0x669de4cb66b8444684e59ada8f3cd4729ddb9d4e3d2d7b1d361b59fe0ba96aa0",
"head_slot": "3775735"
},
"metadata": {
"seq_number": "2",
"attnets": "0x0000000000000600",
"syncnets": "0x08"
},
"agent_client": "Prysm",
"last_received_msg_unix_ts_ms": 1741211227122,
"last_status_unix_ts_ms": 1741211227062,
"connected_unix_ts_ms": 1741211226993
}
Pectra attestation bug
As Lodestar continued to build a Holesky fork that was quickly syncable to help rescue Holesky, we discovered an attestation bug specific to Electra, leading to no aggregate inclusions and producing very bad aggregated attestations ourselves. This made our validator performance very poor while trying to rescue the Holesky chain, and we were not as effective in helping to finalize the chain. The included fix, which uses the correct subnet for validating gossip attestations, was then merged into the holesky-rescue branch shortly after Holesky finalized.

This devastating validator performance bug should have been caught during our Pectra testing. Sadly, it was not seen due to our lack of internal testing visibility on devnets.
ChainSafe now runs devnet nodes with standardized Lodestar metrics used by our testing fleet. Developer ergonomics is key and having familiar tooling, profiling and dashboards is key to proper node monitoring. This will allow us to utilize our internal observational metrics and dashboards to visually inspect performance metrics on EthPandaOps devnets before they occur on public testnets.
Other Considerations for Future Implementation
Lighthouse included a disable-attesting feature, which is used to avoid flooding the beacon node while syncing and removes an additional overhead of dealing with attestation requests: https://github.com/sigp/lighthouse/pull/7046
Leader implementation for disaster recovery should be brainstormed. What would it look like if the community needed to socially agree to nudge the mainnet down a mutually agreed-upon path? Perhaps consensus clients should have the ability to ingest an anchor state on any fork in case of emergency.
As an alternative to blacklisting bad block roots, we are attempting to make a "pessimistic sync" work as an alternative via https://github.com/ChainSafe/lodestar/pull/7511.
Summary
Holesky was a great exercise and provided valuable fixes for all client teams. We believe that non-finality devnets should be prioritized as part of hard fork readiness testing so we have more opportunities to test unhappy cases of network turbulence. This experience helped us ask important questions, even though this may not be the emergency response plan we would consider for mainnet. There are many uncontrollable aspects of mainnet where a rescue reminiscent of Holesky would not be feasible. However, some of the features and fixes developed from this incident may be useful if we experience chain splits or finalize bad blocks in the future.
Contribute to Lodestar!
At ChainSafe, we’re constantly seeking exceptional talent to join our teams and welcome contributors to the Lodestar consensus client. To any TypeScript developers looking to take on challenges and push the boundaries of the JavaScript ecosystem, get in touch!
To get involved, visit our GitHub repository
If you wish to contact the team, join Chainsafe's Discord in the #lodestar-general channel or explore our job openings page. Alternatively, you can email us at info@chainsafe.io.
Remember to visit our official website and follow us on Twitter for more updates.
Lodestar is built and maintained by ChainSafe, a leading blockchain R&D firm.