BABE Epoch Changes
A look at how an epoch works within BABE, Polkadot's block production mechanism.


BABE execution happens in sequential non-overlapping phases known as an epoch
– Polkadot Docs
Epochs are sequentially indexed periods during which authorities are selected to produce blocks. The length of an epoch is pre-defined in the runtime genesis configuration and cannot be changed after the chain has started.
Each epoch has a fixed amount of slots, which are equal-length periods (e.g. seconds) within an epoch. They are also sequentially indexed, and their indices are called slot numbers. Each slot within an epoch is assigned to an authority throughout a lottery process that runs at the very start of an epoch.
It is important to mention that slots relate to real-world clock time, which is why they can be skipped and, by extension, why epochs can be skipped as well.

How is an authority assigned to a slot?
There is no central point that decides which slot belongs to each authority. What does happen is that the authority itself runs a verifiable random function (VRF) that produces a pseudorandom output and a proof of authenticity that anyone can verify. Then, it compares this pseudorandom output with a threshold. If it is less than the threshold, then the authority is required to produce a block.
You might ask: Okay, but how is the epoch related to how an authority claims slots?
Good question! The short answer is randomness and primary probability, both of which are necessary to correctly produce and validate blocks in any epoch.
Everything starts at Genesis Chain Spec
The Genesis chain spec contains all the information needed to build the Genesis block. It also includes the runtime wasm blob, which exports the BabeApi_configuration function. This function returns the necessary information, defined in the BabeConfiguration struct, to set up the verifiable random function and the threshold as the initial authorities, the randomness, and the primary probability, which is a tuple of integers (C1, C2).
- The VRF needs the provided randomness (Primary Block Production Lottery)
- The threshold needs the primary probability tuple integers and the size of the authorities list (Winning threshold)
With this, you have everything you need to either claim a slot to produce a block or validate a block while syncing from genesis on epoch 0, until epoch 1 starts.
The Runtime is required to provide the BABE authority list and randomness to the host via a consensus message in the header of the first block of each epoch.
– Polkadot Spec - 11. Consensus
Once the chain starts, the runtime provides the information retrieved from the genesis spec through issued blocks. However, only the first block in an epoch will contain the relevant information.
The first non-genesis block (block #1) is the first block of epoch 0. Its header contains the BABE authority list and randomness for the next epoch, in this case, epoch 1.
Then, a host client will be made aware of the blocks, as this information is necessary to correctly claim slots before an epoch and validate the correct blocks within it.
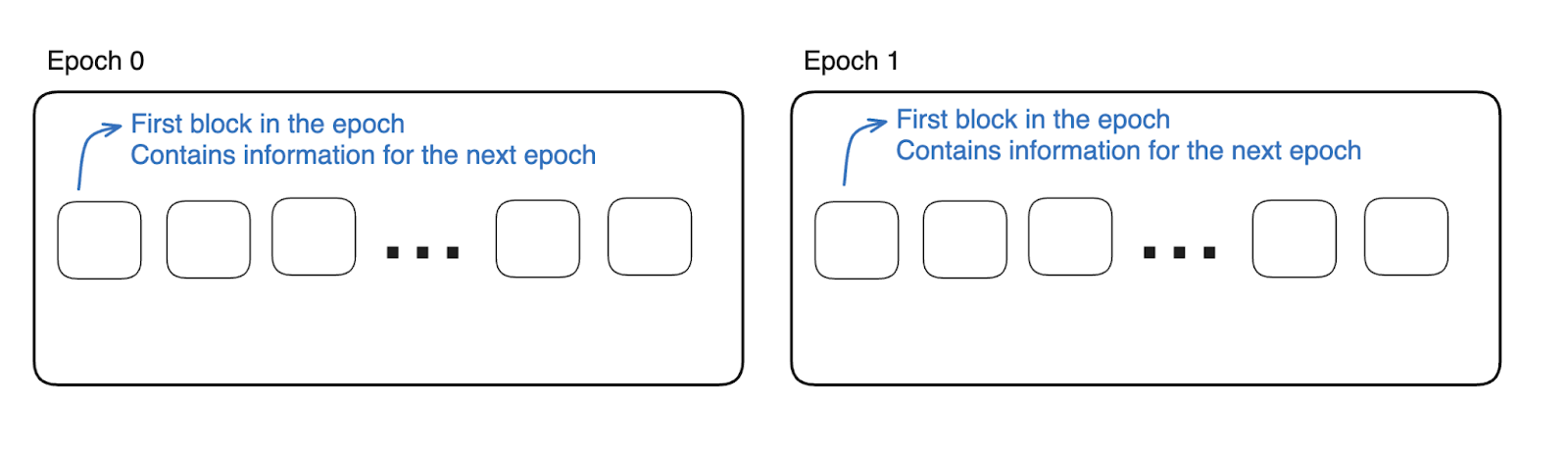
The messages are then encoded in the header digest and are known as Consensus Messages.
Currently, there are three types of BABE Consensus Messages:
This raises the question: How does the runtime know when a new epoch should start?
Jump into FRAME internals
Before answering that, we need to understand what a session is and how it relates to an epoch.
In the Session substrate FRAME Pallet, it's described as:
A period of time that has a constant set of validators. Validators can only join or exit the validator set at a session change. It is measured in block numbers. The block where a session is ended is determined by the ShouldEndSession trait. When the session is ending, a new validator set can be chosen by OnSessionEnding implementations.
– paritytech/polkadot
Noticing a similarity to how epochs are defined? There are actually some slight differences. While both sessions and epochs are sequentially indexed, sessions always increment by 1, whereas epochs don't have to. Simply put, epochs can be skipped, but sessions can't. For example, epochs might go from 1, 2, 5, 10, to 11, while their respective sessions would be 1, 2, 3, 4, 5, and so on. Another notable difference is that sessions delegate the responsibility of calculating when they should end and start to BABE.
The BABE FRAME Pallet implements two traits defined in the Session FRAME Pallet, SessionHandler and ShouldEndSession. Both are responsible for calculating if a given block slot number is ahead of the end slot for the current epoch. As the runtime keeps track of the start slot for a given epoch, the following comparison gets made:
epoch_start_slot + epoch_duration < current_block_slot_number
– Polkadot BABE FRAME Pallet - should_epoch_change
The runtime checks if the session should end in block initialization. If the current one should end, then the session Pallet calls the method rotate_session, which basically updates the authority set and defines the next authorities that will compose the Consensus Message for the upcoming epoch, which is handled by BABE's Pallet.
Skipped epochs
As we previously saw, the runtime provides the host with the necessary information for the next epoch beforehand, but what happens if there is no first block in a specific epoch or, even worse, no blocks at all for n epochs?
Epoch numbers (indexes) might not be contiguous, the block production mechanism may not work correctly, and all the slots for an epoch or more may be left empty. When this happens, it's essential that both runtime and host are aware of what's going on.
Here’s an example:
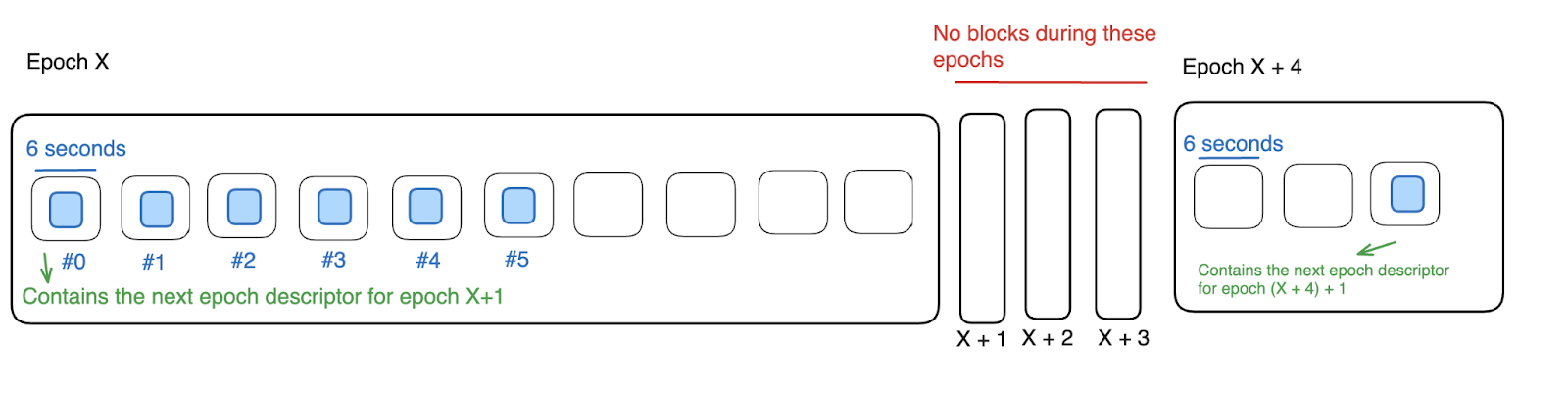
Consider an epoch duration of 1 minute, divided into 10 slots, each lasting 6 seconds. This means a block should be produced every 6 seconds. Now, imagine that in epoch X, the last block was produced at slot #5. After that, no more blocks were produced until slot #2 of epoch X + 4.
How should the host behave in this case? What information should it use to validate a block appearing four epochs later? Or, once the block production mechanism is fixed, how should the validator claim slots and check if it can produce blocks?
The Polkadot spec tells us:
[If] the epochs E + 1 to E + k are skipped (i.e., BABE does not produce blocks), then the epoch data is used by the epoch E + k + 1.
– Consensus Messages, Polkadot Spec
So, what should the host client do?
Once it notices that more than one epoch was skipped, it uses the available data from the last previously unskipped epoch. This is similar to how Epoch Configs are handled. The supplied configuration data will be used from the next epoch onwards. If no epoch data appears, you must use the latest available one!
Regarding the runtime, since it stores the latest epoch index, it can easily find if one or more epochs were skipped. To calculate the current epoch index, the runtime needs to know the current slot, the genesis slot (the slot number for the first non-genesis block) and the epoch duration.
(current_slot - genesis_slot) / epoch_duration
– Substrate Primitives - epoch_index
The runtime will then compare that to the previously stored epoch index. If it hasn't grown by 1, then epochs were skipped.
The runtime should also have a mechanism to tie together sessions and epoch indices, as they can't match if an epoch skip occurs. For that, the runtime holds BoundVec(epoch, session), which is basically a vector of tuples. It stores the latest 100 skipped epochs, enabling the runtime to validate equivocation proofs by knowing the active session index during specific epochs.
Okay, we know the runtime stores skipped epochs, but some things are still missing. What information should the runtime use to create and issue a BABE Consensus Message? Where should it get the next VRF and set of authorities?
The session Pallet defines the set of authorities that will be active in the current session/epoch and those that will be used in the next epoch, so the runtime has the information all ready to go.
Regarding randomness, the BABE Pallet is responsible for accumulating randomness during the current epoch x to use for epoch x + 1. As three epochs were skipped, the runtime uses the accumulated randomness for epoch x + 4.
The runtime generates randomness by concatenating all the VRF outputs from the previous period.
– paritytech/polkadot-sdk
TL;DR
- The BABE protocol features a meticulous design for block production through epoch and slot system
- Each epoch facilitates a decentralized lottery process for assigning block production slots to authorities
- Integration of epochs with sessions and careful handling of skipped epochs ensures blockchain resilience and security
- BABE maintains integrity and continuity of the blockchain while enabling validators to accurately claim and produce blocks
More Gossamer
- Chat directly with the team → Discord
- Learn more by checking out the → Docs
- Keep a tab on the progress → Twitter
Interested in joining the team? Have a background in protocol engineering? Check out the job opening below 👇

About ChainSafe
ChainSafe is a leading blockchain research and development firm specializing in protocol engineering, cross-chain interoperability, and web3 gaming. Alongside its contributions to major ecosystems such as Ethereum, Polkadot, and Filecoin, ChainSafe creates solutions for developers across the web3 space utilizing expertise in gaming, interoperability, and decentralized storage. As part of its mission to build innovative products for users and improved tooling for developers, ChainSafe embodies an open-source and community-oriented ethos to advance the future of the internet.